Time flies like an arrow. Fruit flies like a banana.
At first glance, these two sentences seem almost identical — the same structure, the same rhythm, thesame words reused. But they mean completely different things: the first is a simple observation about speed. The second is a sentence about insects and their taste in fruit.
A human reads both and understands immediately. A machine like ChatGPT? Not so much. For decades, researchers in language AI tried to build systems that could tell the difference — not just by breaking down the grammar, but by understanding the meaning underneath it.
That was the early vision: machines that understand language the way humans do. And for a while, that’s what researchers tried to build.
Then something changed: we stopped trying to make machines understand. Instead, we trained them to predict.
That’s the shift that gave us ChatGPT and the Large Language Models (LLMs)…
From Meaning to Prediction
In the early decades of language AI, the goal wasn’t just to make machines sound fluent. It was to make them understand.
That meant teaching computers how to analyse sentence structure, assign roles like subject and object, resolve ambiguity, and connect words to meaning. Researchers built systems based on logic trees, grammar rules, and the relationship between words — carefully constructed to reflect how language is supposed to work.
But they quickly ran into trouble as language is quite messy in practice.
Take a sentence like:
“He gave her dog biscuits.”
Is the man giving her dog some biscuits? Or is he giving her some dog biscuits?
A human figures it out immediately — based on context, tone, through facial expression. But to a machine, both interpretations are equally valid. The structure doesn’t tell you enough. And if that one sentence can bend in two directions, imagine trying to scale that across dialects, slang/sheng, jokes, and cultural nuance.
Meaning-based systems were ambitious but couldn’t handle the complexity. By the early 2010s, it became clear that they couldn’t scale.
So the interest shifted.
Instead of trying to teach machines how language works, researchers started teaching them what usually comes next. No longer understanding, but prediction.
And that shift is what gave us today’s large language models (LLMs).
What LLMs Actually Do
When you type a question into ChatGPT (or Claude or Gemini), it doesn’t search the internet. It doesn’t look up facts, apply logic, or remember what it told you last time. What it does is something both simpler and more surprising:
It predicts the next most likely word — or rather, the next most likely token — based on everything it has seen before.
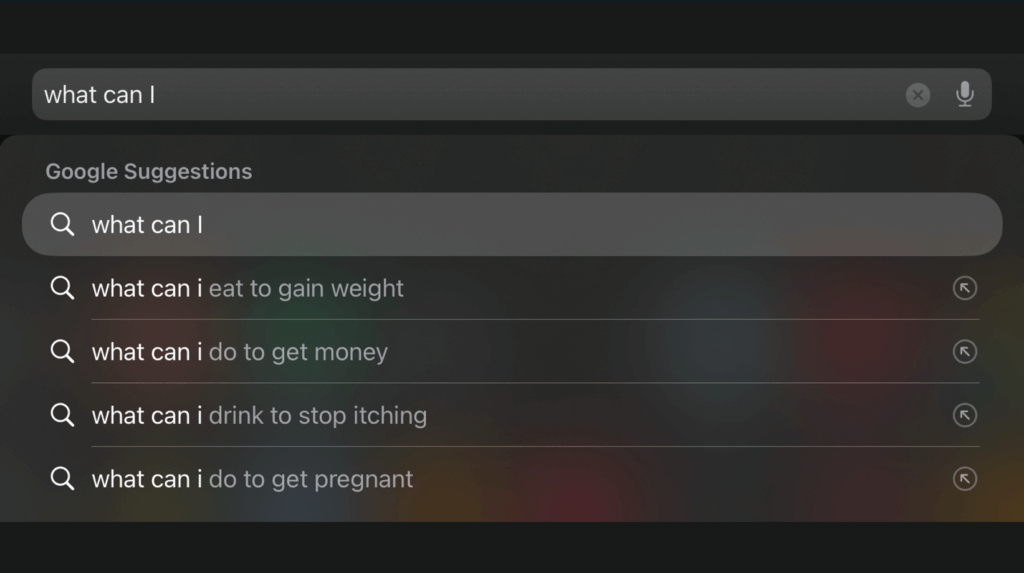
Think Google autocomplete — but for everything
If you’ve ever started typing into Google — say, “How to make” — and watched it autocomplete with things like “pancakes,” “money online,” “a resume,” or “a bomb” (depending on where and when you’re searching), you’ve already seen predictive text in action.
Google doesn’t know what you meant. It just knows what other people tend to type next.
Large language models like ChatGPT work in the same way, but instead of completing a short search phrase, they can generate full essays, stories, proposals, arguments, or explanations. One token at a time. The difference is scale, not logic.
Wait! But what is a token?
A token is a chunk of text — not always a full word. It could be:
- A short word: “cat”, “go”, “fast”
- A piece of a longer word: “under” + “stand” + “ing”
- Punctuation, numbers, or even spaces
So if you ask an LLM to explain something, it doesn’t generate the full sentence at once. It predicts: first token → then the next → then the next — adjusting at each step based on what it just said.
That’s how it can speak fluently across hundreds of domains without actually “knowing” anything.
How does that work?
All modern LLMs whether it’s OpenAI’s ChatGPT, Anthropic’s Claude, Google’s Gemini, or Meta’s LlaMA, are all based on the same core architecture: the transformer.
Its key innovation is attention: a mechanism that helps the language model figure out which parts of your input matter most when choosing the next token. So for example if you say “The CEO of the company announced…”, the model knows to pay attention to “CEO” when predicting the next word, not just the last three tokens.
This lets LLMs stay coherent over long texts, adapt their tone, and answer in context — not because they understand what’s happening, but because they’re really good at spotting patterns in how language is typically used.
How are they trained?
Training a language model is like showing it billions of half-finished thoughts and making it guess how they end. It sees part of a sentence, predicts the next token, checks whether it was right, and adjusts itself when it’s wrong. This happens trillions of times during training.
Behind the scenes, the model is tweaking hundreds of billions of internal settings called parameters to fine-tune how it weighs different types of patterns.
That’s what gives it its fluency. Not intelligence, not reasoning, just finetuned prediction.
Why it looks intelligent
The outputs feel like real understanding:
- It can summarize a legal document
- Answer a philosophical question
- Draft an email in your tone of voice
But what it is really doing is:
- Recognizing patterns it has seen
- Completing the sentence based on probability
- Never truly “knowing” what it’s saying
It’s trained to sound right, not to be right. And that is by design.
Why This Matters
If large language models simply completed sentences like Google’s search bar, we wouldn’t worry too much.
But they don’t stop at suggestions. They generate full responses. They draft project proposals, summarise contracts, explain medical symptoms, suggest investment strategies, write customer letters, and interpret laws. And when they do all that in clean, confident language, it’s easy to assume there’s understanding behind the words.
But there isn’t.
Because LLMs don’t work from facts, logic, or intent, they work from probability. Which means that their outputs can be:
- Fluent but false — confidently stating something that never happened
- Biased — reflecting whatever patterns were most common in their training data
- Inconsistent — giving different answers to the same question on different days
- Unverifiable — with no source, rationale, or traceable logic
LLMs don’t remember. They don’t reason. They don’t fact-check. They simply complete based on what sounds most likely.
This doesn’t mean LLMs are useless. It simply means they are useful within constraints.
If you treat them like search engines, they mislead. If you treat them like advisors, they improvise. If you treat them like generators — for first drafts, alternative phrasings, or rough outlines — they are remarkably helpful.
But knowing how they produce what they say is the difference between using them wisely… and using them blindly.
LLMs like ChatGPT, Claude, and Gemini are already showing up in everyday work:
Someone rewrites an email to make it sound more professional. Someone else summarises a long policy document into bullet points. Another person drafts a first version of a funding proposal, or a product description, or a set of training materials.
These uses aren’t always mentioned and often they’re not even discussed. The output just becomes part of the workflow. The issue isn’t that this is happening. It’s that people often don’t know what the model is doing — or not doing — underneath.
They treat the outputs as neutral, logical, and fact-based when in reality they’re fluent guesses drawn from pattern recognition. When people don’t understand how these systems work, they start relying on them in ways they were never designed to support.
That has real consequences. Because the moment an LLM’s output gets copied into a report, sent to a client, or pasted into a proposal, it stops being an experiment. It becomes part of the record and part of how decisions are derived at.
That’s why it’s worth being clear: not just about what these tools can do, but also how they work.
We’ve written a short Strategy Note for those starting to integrate LLMs into real workflows. It outlines where the risks show up, what to look out for, and how to design for responsible use.
